Traditional OCR-specialized models have long focused on text recognition itself and generally lack the ability to extract structured key information from documents. General-purpose VLMs show promise for KIE, but their accuracy in professional OCR scenarios is often unsatisfactory. QianfanOCR aims to break this tradeoff: it keeps OCR accuracy at the level of specialized models while making KIE a core model capability. This article shares the key engineering practices behind our KIE dataset construction, including a full-chain high-quality data construction system covering hybrid labeling, rule-based cleaning, and distribution enhancement, which forms a closed loop from label synthesis and quality screening to sample optimization, substantially reducing hallucinations while improving data quality and scenario coverage; a semantic generalization strategy driven by synonymous Key replacement, which helps the model move beyond literal matching and adapt to diverse field expressions; and a four-stage automated rejection-sample generation pipeline, which teaches the model to say "no" when a requested field is invalid. Experiments show meaningful gains in recall, extraction accuracy, and rejection precision.
Background & Task Definition
In document intelligence, Key Information Extraction (KIE) is the core step that connects "visual perception" with "structured output". Its goal is to convert visually scattered information in document images into machine-consumable Key-Value JSON. Depending on task scope and the depth of semantic understanding required, KIE tasks can usually be divided into two major types:
Full Extraction
This task emphasizes "what you see is what you get": the model must capture all visible key-value information in the image. In a physical examination report, for example, the model must accurately identify each test item along with its indicator, value, and unit. The main difficulties are spatial association modeling under complex layouts and preserving completeness in long-sequence outputs.
Targeted Field Extraction
This task extracts information according to a user-defined field list. Compared with full extraction, it places higher demands on the model's semantic understanding and cross-template generalization. The model must not only recognize text, but also understand the implicit semantic mapping between user fields and the original wording in the image.
Typical scenario: in a medical insurance settlement form, the user may request "Admission Time", while the original document records it as "Admission Date". Similarly, "Medical Insurance Payment" may correspond to "Total Fund Payment". Different wording, same meaning - this is the central challenge in targeted field extraction.
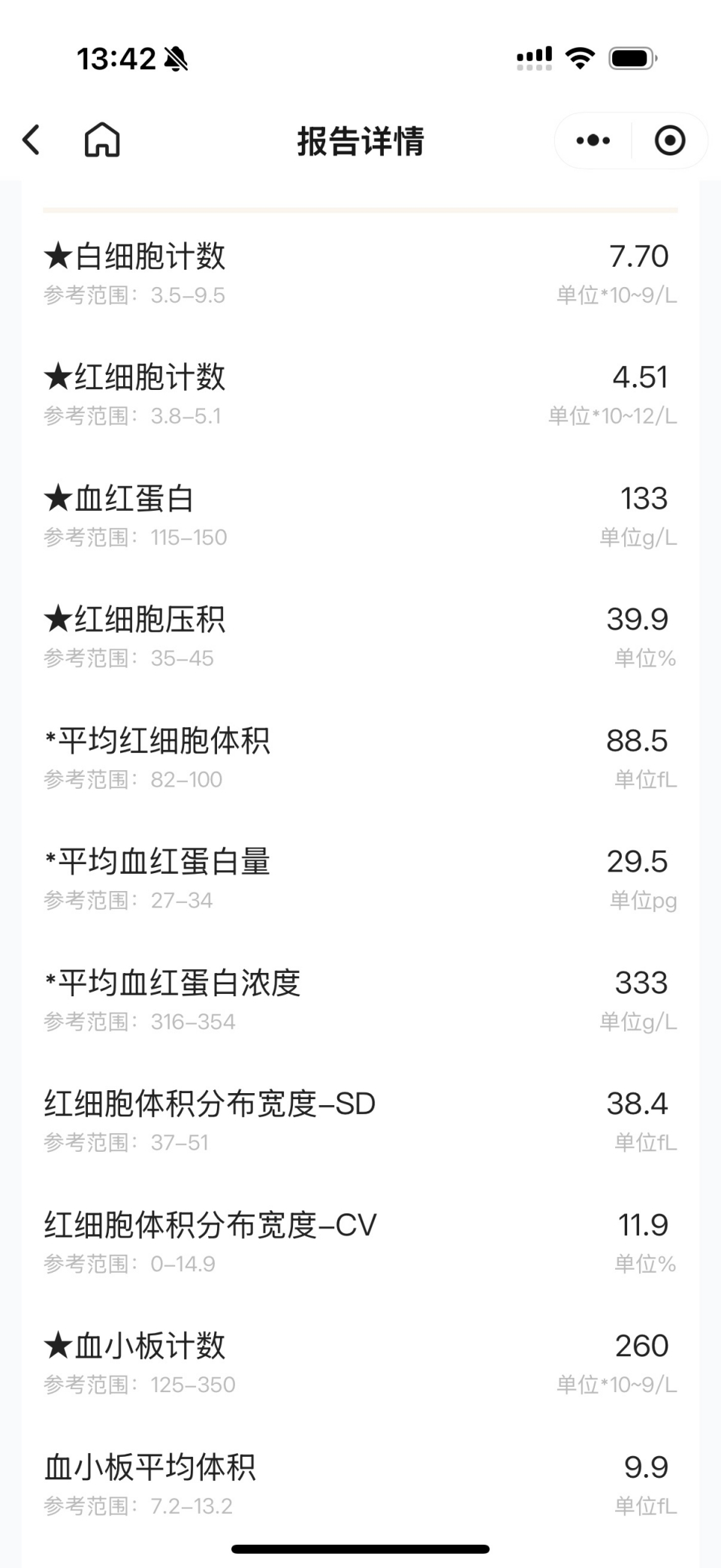
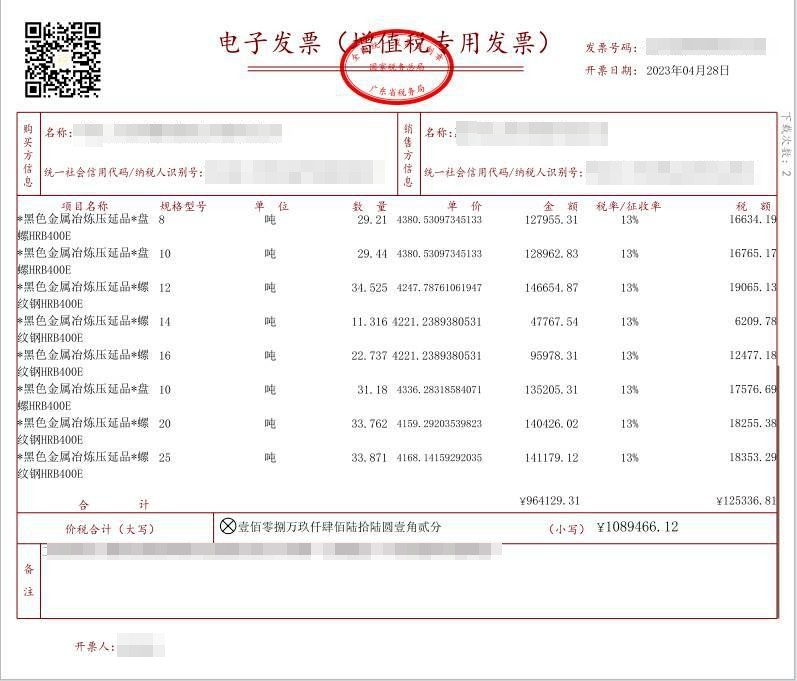
Why Do We Need an End-to-End VLM?
Traditional OCR-specialized vision-language models, such as dotsocr and glm-ocr, are constrained by their training paradigms and model scale. They usually handle only text recognition and struggle with structured information extraction. The seemingly reasonable two-stage "OCR + LLM" pipeline has a fundamental flaw: layout information is silently lost in the intermediate step, which causes a series of hard-to-fix cascading problems. Two typical examples are listed below:
📌 Issue 1: Key-Value Misalignment
After OCR converts the image into text, the spatial topology of the original layout collapses. The model can easily pair unrelated keys and values, producing extraction results with mismatched fields.
📌 Issue 2: Cascading Errors in Complex Tables
In complex tables with multiple rows and columns, even a small alignment error in the OCR stage can be amplified by the downstream LLM, eventually creating an avalanche of errors that is difficult to trace.
Beyond these examples, semantic recovery under stamp occlusion, cross-page content aggregation, and unified understanding of mixed handwriting and printed text can all lose information at the "OCR -> LLM" handoff. These issues are only the tip of the iceberg.

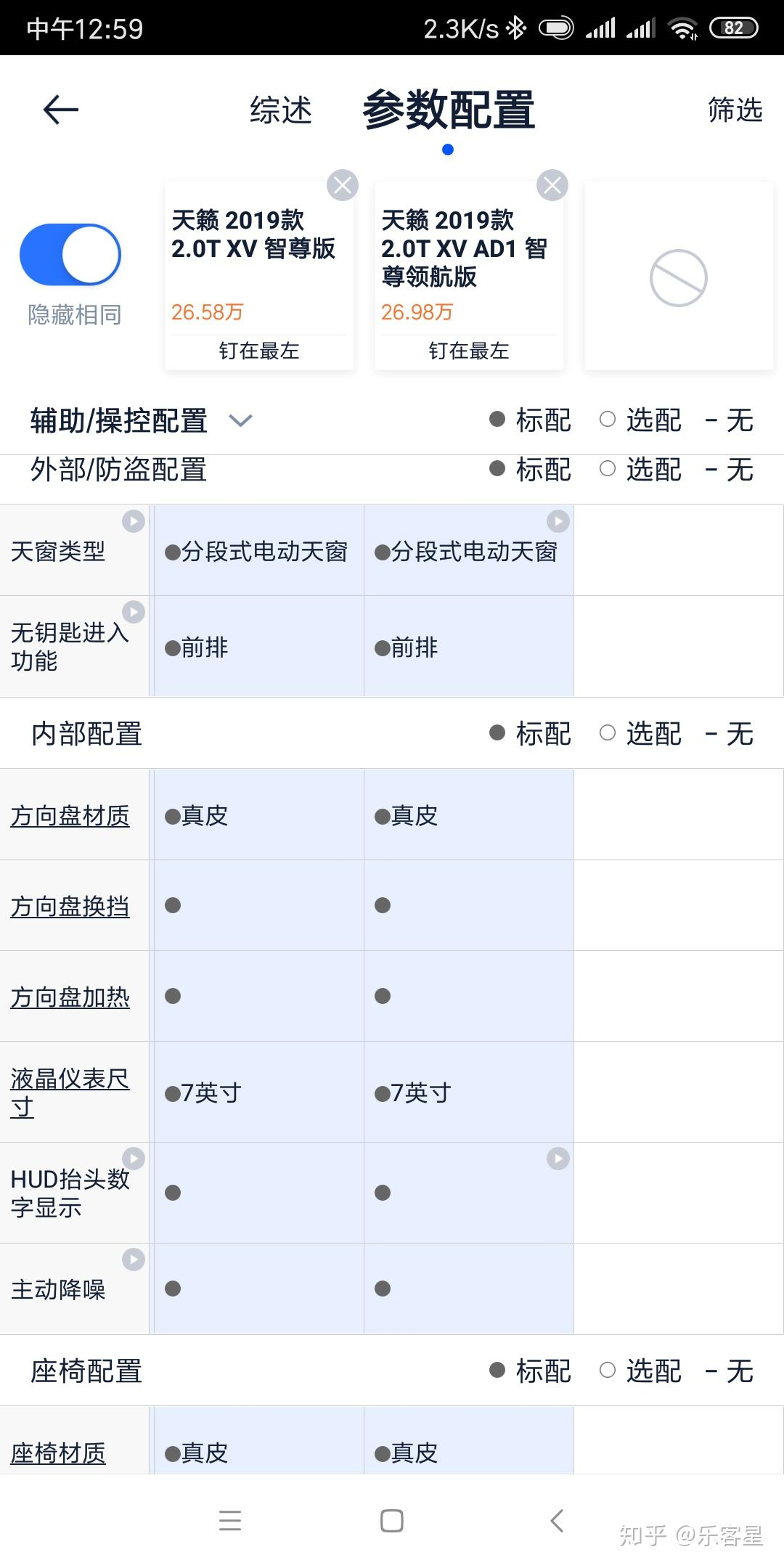
An end-to-end VLM, such as QianfanOCR, integrates perception, understanding, and structured extraction, performing inference directly on the image. This avoids information loss introduced by intermediate steps and shows clear advantages over two-stage pipelines in Key-Value alignment accuracy and robustness on complex tables.
Building High-Quality Training Data
Data defines the ceiling of model capability. For the two core tasks of full extraction and targeted field extraction, we built an end-to-end high-quality data production process around three dimensions: data synthesis, annotation quality, and cleaning standards. The goal is not only to have data, but to have good data.
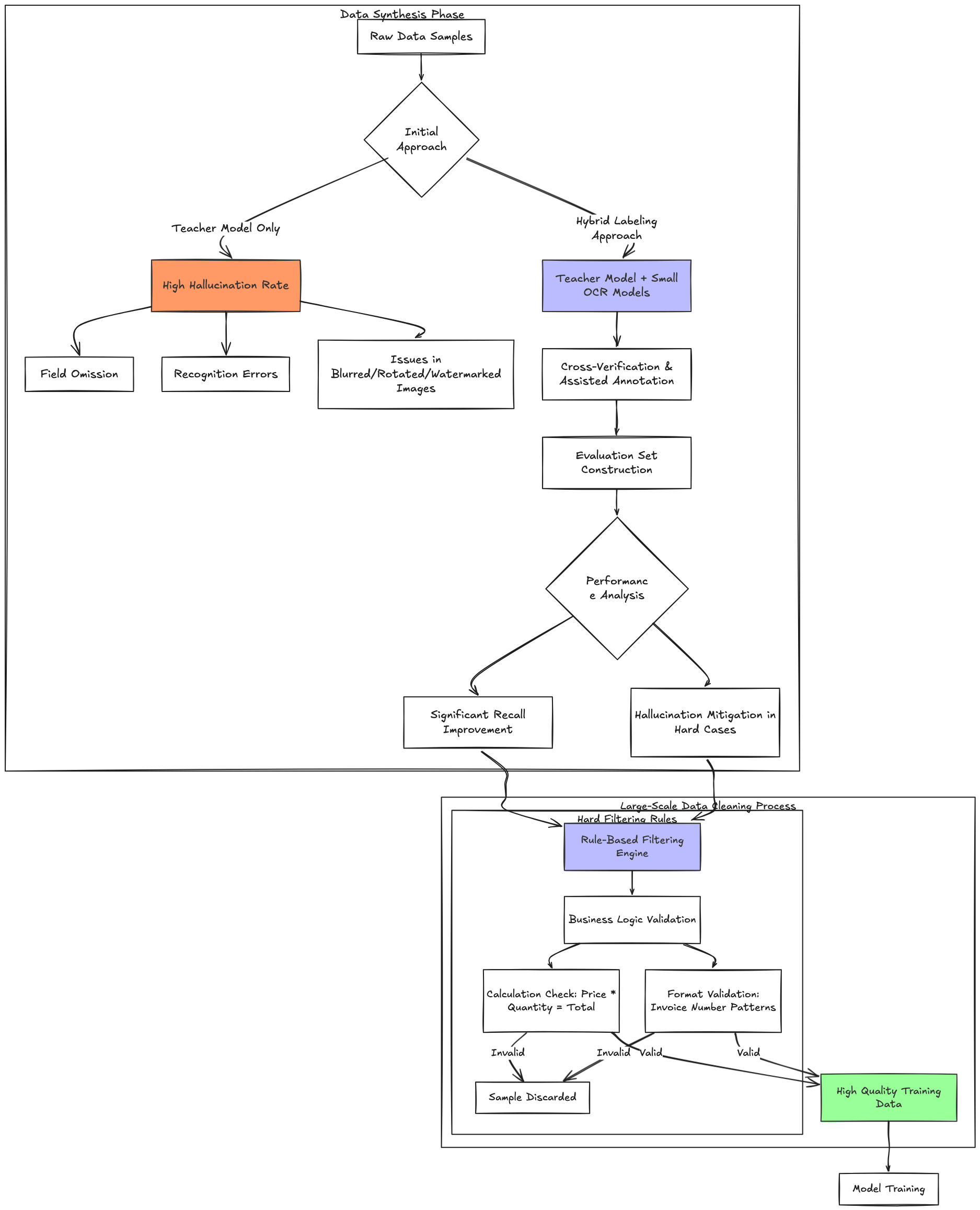
Data Synthesis Stage
Our initial idea was to use a large teacher model to generate annotated data, or GT, in batches. Practice led to a different conclusion: under complex conditions such as blur, rotation, deformation, and watermark interference, the teacher model's hallucination rate rose sharply. Missing fields and recognition errors appeared repeatedly, making annotation quality hard to guarantee.
We therefore moved to a more robust Hybrid Labeling Approach. A traditional lightweight OCR model is introduced as an auxiliary labeling tool to complement the teacher model. Cross-validation filters out low-confidence samples, and a dedicated evaluation set for these hard cases is maintained for continuous monitoring. Experiments show that this approach brings meaningful gains in both recall and hallucination suppression.
We built a hard-case evaluation set for scenarios such as blur, rotation, and watermarks, then compared the recall of the two labeling strategies on structured field extraction. On high-frequency document types such as ID/card documents and invoices, the hybrid labeling approach significantly improved recall while greatly suppressing hallucinated outputs from the teacher model on hard samples.
| Document Type | Teacher-Only Model | Hybrid Labeling | Gain |
|---|---|---|---|
| ID/Card Documents | ~89% | ~98% | about +9 pp |
| Receipts & Invoices | ~85% | ~94% | about +9 pp |
| Overall Average | Absolute recall improvement | about +10 pp | |
Data Cleaning Stage
Completing annotation is not enough. We established a large-scale rule-filtering system aligned with business semantics. Each training sample goes through two strict compliance checks, preventing dirty data from entering the training set at the source:
- Computational consistency check: automatically identifies and removes numeric self-consistency errors such as "unit price x quantity != total amount", ensuring arithmetic relationships between fields are valid
- Format compliance check: verifies structured fields such as invoice numbers, date formats, and ID numbers against industry standards, filtering abnormal samples that do not meet the rules
The two checks form a serial filtering gate: if either check fails, the sample is discarded. Only samples that pass both checks enter the final training set. This strict admission standard gives High Quality Training Data high accuracy and strong consistency, creating a solid data foundation for model training.
To quantify the real benefit of data cleaning, we ran an ablation study on an in-house multi-scenario KIE evaluation set covering seven high-frequency verticals, including bank receipts, VAT invoices, medical settlement forms, and medical invoices:
| Method | Average Score | Change |
|---|---|---|
| Raw Data (Baseline) | ~58.4 | - |
| + Data Cleaning (computational logic + format filtering) | ~62.3 | about +3.9 |
Rule filtering alone increased the model's average score across seven in-house subtasks by about 3.9 points overall, with stable positive gains on every subtask. The benefit is especially clear in long-tail scenarios with complex layouts and dense fields. This confirms a simple point: the cleanliness of training data has a greater impact on the model ceiling than simply piling up more data.
Sample Optimization: Distribution Reshaping and Image Augmentation
Annotation and cleaning ensure that data quality is high enough. Sample optimization ensures that coverage is broad enough. We further optimized the dataset from two angles: data distribution reshaping and image-level augmentation.
📊 Data Distribution Optimization
We actively mine and supplement difficult samples such as long-sequence details, dense layouts, and multi-level nested structures. Training ratios are dynamically adjusted according to scenario distribution. The weight of simple samples is intentionally reduced so the model faces boundary cases during training instead of staying in a comfort zone.
🔄 Image Augmentation Strategy
We systematically introduce geometric transformations, including rotation, perspective distortion, and crop jitter, as well as image degradation simulations such as blur, noise, low resolution, and watermark occlusion. This exposes the model to realistic disturbances during training, helping it remain stable on scanned and photographed documents.
The two dimensions reinforce each other. Distribution-level supplementation solves limited exposure, while augmentation-level disturbance simulation improves resistance to interference. Together, they raise the model's robustness and generalization in complex real-world scenarios.
First, consider the effect of distribution reshaping. We adjusted the training-sample ratio by layout complexity so the model received sufficient training on long-tail complex layouts. Results show that F1 on the target scenario increased steadily by about 0.7 points, while other scenarios were largely unchanged. This suggests that distribution reshaping can precisely improve the target layout without introducing negative transfer.
Next, consider the effect of image augmentation. We replaced samples from key scenarios in the training set with augmented versions covering rotation, blur, watermark occlusion, and other disturbances, while keeping all other training data unchanged. The results are shown below:
| Evaluation Scope | Change |
|---|---|
| Augmented target scenarios | F1 improves by about +2 to +4 |
| Other scenarios without augmentation | Roughly unchanged (no negative transfer) |
| Overall Average | about +1.1 |
The gains are highly concentrated in the augmented target scenarios, while other categories remain basically unchanged. This creates a clean causal chain from targeted augmentation to targeted benefit, with overall average F1 improving by about 1.1 points.
Key Semantic Generalization for Stronger Generalization
In real business scenarios, the same information field often appears in many different expressions. "Admission Date" and "Admission Time" can share the same meaning, but they are different strings. If the training data contains only one expression, the model may fail when it encounters an unfamiliar one, causing the match rate to drop sharply.
To overcome this bottleneck, we designed a data augmentation strategy based on synonymous Key replacement. By systematically expanding the expression space of fields, the model learns to understand meaning instead of memorizing literal strings:
Synonymous Key Generation
A large language model semantically expands the original field names and automatically generates candidates with equivalent meanings but varied wording. This builds a broad synonym table for each original Key, creating the source material for subsequent data augmentation.
Random Key Replacement for Training Samples
During data construction, field names in the Prompt are randomly replaced, with a certain probability, by alternative expressions from the synonym table. This generates large numbers of training samples where the user's wording differs from the wording in the image. The Prompt also explicitly guides the model to focus on semantic correspondence rather than string matching, fundamentally changing what the model learns.
Synonym Expansion Examples
Admission Date ->
Total Fund Payment ->
After this augmentation training, the model no longer depends on literal alignment. It builds a real semantic recognition capability for differently named but equivalent fields. When facing user-defined field expressions, the model maintains stable and accurate extraction output, achieving a qualitative improvement in open field-definition scenarios.
To quantify the additional benefit of diversified Key sampling, we added synonymous Key replacement on top of the data-cleaned version and compared the results before and after:
| Method | Average Score | Change |
|---|---|---|
| After Data Cleaning (Baseline) | ~62.3 | - |
| + Diversified Key Sampling | ~64.0 | about +1.7 |
After data cleaning had already pushed the score to ~62.3, diversified Key sampling brought another improvement of about 1.7 points, completing the final piece of field semantic generalization. Combined with the +3.9 gain from data cleaning, the two strategies deliver an overall gain of about +5.5, with stable positive results across all subtasks.
Rejection Capability Optimization for Better Boundary Recognition
A trustworthy KIE system must have two distinct but equally important abilities: accurately extracting fields that exist, and decisively rejecting fields that do not exist. If the model makes up an answer instead of honestly rejecting an invalid query, hallucinated output can quietly pollute the entire structured result.
To address this weakness systematically, we designed a VLM-based automated rejection-sample generation pipeline. The pipeline constructs diverse, high-quality rejection training samples in batches through four stages:
Rejection Instruction Generation
Based on the image content, the model analyzes the context and style of the original Prompt, then naturally inserts rejection instructions into a new Prompt through six embedding styles, such as an opening note, caution statement, or output-format constraint. At the same time, a rejection value is randomly selected from 16 multilingual options, such as "None", "N/A", and "This field does not exist", ensuring the model learns multiple ways to politely and firmly say no.
Rejection Key Generation
After observing the image, the model generates two representative types of rejection fields: empty-value Keys, where the field exists in the image but its corresponding value is empty, and false Keys, which are related to the document topic but do not actually appear in the image. These two field types closely simulate common business cases where users over-ask or guess fields.
Key Position Randomization
Based on the real distribution of fields in the image, rejection Keys are randomly inserted among the original field sequence instead of being concentrated at the beginning or end. This deliberately breaks positional patterns, preventing the model from learning shortcuts such as "fields at the end should be rejected" and preserving natural field ordering and generalization.
Final Sample Generation
The original GT is used as an anchor to keep existing field values accurate. Rejection fields are filled with the currently specified rejection value. The output field order is strictly aligned with the Prompt, producing a complete training sample with standardized format and reliable annotations.
Each of the four stages independently uses image content in its decision-making process, maximizing the accuracy and diversity of every annotated sample. After large-scale production with this pipeline, the model's rejection accuracy when facing invalid fields improves significantly, and the probability of hallucinated output is effectively suppressed. The model finally learns to know what it knows and what it does not.
| Core Metric | Meaning | Before | After | Change |
|---|---|---|---|---|
| Hallucination Rate (Fabrication) ↓ | Fabricates values for fields that are not present in the image | ~24% | ~4% | about -20 pp (relative -85%) |
In short, rejection optimization turns the model from one that guesses into one that can say "I don't know". The hallucination rate drops from about one quarter to below one twenty-fifth, without harming the original character-recognition capability.
Conclusion & Outlook
This article focuses on data engineering practice for end-to-end VLMs in Key Information Extraction scenarios. It systematically explains our core methods and key lessons across the full data construction pipeline. The main contributions can be summarized in three points:
- Full-chain high-quality data construction: We built a complete data production system covering "hybrid labeling -> rule-based cleaning -> distribution reshaping and image augmentation". Teacher models and small OCR models collaborate to suppress hallucinations, dual checks ensure data compliance, and distribution optimization plus multi-dimensional augmentation improve scenario coverage, raising both training-data quality and diversity end to end.
- Synonymous Key semantic generalization: LLM-driven synonym expansion and random replacement help the model move away from literal string matching and achieve stable semantic alignment in open field-definition scenarios.
- Four-stage rejection pipeline: Automated construction of diverse rejection training samples gives the model the ability to honestly reject invalid fields and effectively suppress hallucinated output.
Final Results: Public Benchmark Evaluation
To verify the combined effect of these data engineering strategies, we evaluated QianfanOCR against mainstream commercial models and open-source models of similar scale on five public KIE benchmarks. Traditional OCR-specialized models are not included because they lack native KIE capability. The results are shown below:
| Model | Overall (Mean) | OCRBench KIE | OCRBenchv2 KIE (en) | OCRBenchv2 KIE (zh) | CCOCR KIE | Nanonets KIE (F1) |
|---|---|---|---|---|---|---|
| Qianfan-OCR (Ours) | 87.9 | 95.0 | 82.8 | 82.3 | 92.8 | 86.5 |
| Qwen3-4B-VL | 83.5 | 89.0 | 82.1 | 71.3 | 91.6 | 83.3 |
| Qwen3-VL-235B-A22B | 84.2 | 94.0 | 85.6 | 62.9 | 95.1 | 83.8 |
| Gemini-3.1-Pro | 79.2 | 96.0 | 87.8 | 63.4 | 72.5 | 76.1 |
| Gemini-3-Pro | 77.0 | 93.5 | 87.1 | 49.6 | 72.7 | 82.1 |
| Seed-2.0 | 78.0 | 92.5 | 75.6 | 48.9 | 89.6 | 83.4 |
QianfanOCR achieves the highest overall average score, 87.9, across the five KIE benchmarks, outperforming larger commercial and open-source models such as Qwen3-VL-235B-A22B (84.2) and Gemini-3.1-Pro (79.2). Its advantage is especially clear in Chinese KIE scenarios (OCRBenchv2 KIE zh: 82.3), where it is 11 points higher than the next-best Qwen3-4B-VL (71.3), demonstrating the strong gains brought by this data engineering approach for Chinese document understanding.
Current Limitations and Future Directions
Although these strategies have already delivered meaningful improvements in real business scenarios, there is still room for further exploration:
📐 Limitations
The current data construction process still relies heavily on rule-driven cleaning logic and heuristic augmentation strategies. When facing entirely new document types, a certain amount of manual adaptation is still required. In addition, while rejection capability has improved significantly, the model can still make mistakes in extremely blurry or highly ambiguous scenarios.
🔮 Future Directions
We are exploring the introduction of reinforcement learning (RL) into the KIE training process. Reward modeling can further optimize the balance between structured-output completeness and rejection precision. We also plan to use active learning to create an adaptive data-production loop, allowing the model to identify its own weaknesses and drive data supplementation, reducing dependence on manual annotation.
KIE is a key step in turning document intelligence into practical business value. We believe that as data engineering methodology continues to evolve and model architectures keep advancing, end-to-end VLMs will unlock even greater potential in document understanding: not only seeing clearly, but also reading deeply, extracting accurately, and rejecting properly.