Qianfan-VL: Domain-Enhanced Universal Vision-Language Models
Domain Capability Enhancement through Continuous Pre-training | 3B to 70B Parameter Scale
Document Understanding & OCR Enhancement | Reasoning Capability Support
Table of Contents
Core Features
The Qianfan-VL model series is a general-purpose multimodal large model enhanced for enterprise-level multimodal applications. It possesses fundamental general capabilities while offering deep optimization for high-frequency scenarios in industrial deployment. Through three core functions, it precisely meets multimodal understanding needs in different scenarios.
Multi-Size Models
Provides 3B, 8B, and 70B model variants to meet different scenario requirements
OCR & Document Understanding Enhancement
Full-scenario OCR recognition and intelligent understanding capabilities, covering documents, natural scenes, and various application scenarios
Reasoning Capability
Supports chain-of-thought capabilities, demonstrating excellent performance in complex scenarios like mathematics and reasoning calculations
Multi-Size Models Meet Different Scenario Requirements
Provides 3B, 8B, and 70B model variants, allowing enterprises and developers of different scales to find suitable solutions
| Model Name | Context Length | Reasoning Support | Application Scenarios |
|---|---|---|---|
| Qianfan-VL-3B | 32k | Not Supported | Edge real-time scenarios, OCR text recognition |
| Qianfan-VL-8B | 32k | Supported | Server-side general scenarios, fine-tuning optimization scenarios |
| Qianfan-VL-70B | 32k | Supported | Offline data synthesis, complex reasoning computation scenarios |
General Capability Benchmark Performance
Comprehensive comparison of Qianfan-VL models of all scales with mainstream models on standard multimodal benchmarks
| Benchmark | Qianfan-VL-3B | Qianfan-VL-8B | Qianfan-VL-70B | InternVL3-8B | InternVL3-78B | Qwen2.5-VL-7B | Qwen2.5-VL-72B |
|---|---|---|---|---|---|---|---|
| A-Bench_VAL | 75.65 | 75.72 | 78.1 | 75.86 | 75.86 | 76.49 | 79.22 |
| CCBench | 66.86 | 70.39 | 80.98 | 77.84 | 70.78 | 57.65 | 73.73 |
| SEEDBench_IMG | 76.55 | 78.02 | 79.13 | 77.00 | 77.52 | 76.98 | 78.34 |
| SEEDBench2_Plus | 67.59 | 70.97 | 73.17 | 69.52 | 68.47 | 70.93 | 73.25 |
| MMVet | 48.17 | 53.21 | 57.34 | 80.28 | 78.90 | 70.64 | 75.69 |
| MMMU_VAL | 46.44 | 47.11 | 58.33 | 56.11 | 60.78 | 51.0 | 65.78 |
| ScienceQA_TEST | 95.19 | 97.62 | 98.76 | 97.97 | 97.17 | 85.47 | 92.51 |
| ScienceQA_VAL | 93.85 | 97.62 | 98.81 | 97.81 | 95.14 | 83.59 | 91.32 |
| MMT-Bench_VAL | 62.23 | 63.22 | 71.06 | 65.17 | 63.67 | 61.40 | 69.49 |
| MTVQA_TEST | 26.5 | 30.14 | 32.18 | 30.30 | 27.62 | 29.08 | 31.48 |
| BLINK | 49.97 | 56.81 | 59.44 | 55.87 | 51.87 | 54.55 | 63.02 |
| MMStar | 57.93 | 64.07 | 69.47 | 68.40 | 66.07 | 61.53 | 66.00 |
| RealWorldQA | 65.75 | 70.59 | 71.63 | 71.11 | 74.25 | 69.28 | 73.86 |
| Q-Bench1_VAL | 73.51 | 75.25 | 77.46 | 75.99 | 77.99 | 78.10 | 79.93 |
| POPE | 85.08 | 86.06 | 88.97 | 90.59 | 88.87 | 85.97 | 83.35 |
| RefCOCO (Avg) | 85.94 | 89.37 | 91.01 | 89.65 | 91.40 | 86.56 | 90.25 |
OCR & Document Understanding Enhancement
Focuses on two distinctive capabilities: full-scenario OCR recognition and complex layout document understanding, demonstrating excellent performance in multiple benchmark tests and providing high-precision visual understanding solutions for enterprise-level applications
Full-Scenario OCR Tasks
- Handwriting Recognition: Chinese and English handwriting recognition, supporting various fonts like cursive and regular script
- Formula Recognition: Precise mathematical formula recognition and conversion to LaTeX format
- Natural Scene Text Recognition: Text detection in complex environments like street views, signs, and markers
- Card/Document Information Extraction: Structured information extraction from ID cards, driver's licenses, business licenses, etc.
Complex Layout Document Understanding
- Layout Analysis: Automatic recognition of layout elements like titles, paragraphs, charts, and tables
- Table Understanding: Complex table structure parsing, supporting merged cells and multi-level headers
- Chart Understanding: Data extraction and analysis of bar charts, line charts, pie charts, etc.
- Document Q&A: Intelligent question answering and information retrieval based on document content
- Document Parsing: Structured parsing of PDF, Word, and other format documents
OCR & Document Understanding Benchmark Performance
Comprehensive comparison of Qianfan-VL models of all scales with mainstream models on OCR and document understanding professional benchmarks
| Benchmark | Qianfan-VL-3B | Qianfan-VL-8B | Qianfan-VL-70B | Qwen2.5-VL-3B | InternVL3-8B | InternVL3-78B | Qwen2.5-VL-7B | Qwen2.5-VL-72B |
|---|---|---|---|---|---|---|---|---|
| OCRBench | 831 | 854 | 873 | 810 | 881 | 847 | 883 | 874 |
| AI2D_TEST | 81.38 | 85.07 | 87.73 | 77.07 | 85.07 | 83.55 | 80.472 | 83.84 |
| OCRVQA_TEST | 66.15 | 68.98 | 74.06 | 69.24 | 39.03 | 35.58 | 71.02 | 66.8 |
| TextVQA_VAL | 80.11 | 82.13 | 84.48 | 79.09 | 82.15 | 83.52 | 84.962 | 83.26 |
| DocVQA_VAL | 90.85 | 93.54 | 94.75 | 92.71 | 92.04 | 83.82 | 94.91 | 95.75 |
| ChartQA_TEST | 81.79 | 87.72 | 89.6 | 83.4 | 85.76 | 82.04 | 86.68 | 87.16 |
Reasoning Capability
8B and 70B models support chain-of-thought capability activation through special tokens, covering complex chart understanding, visual reasoning, mathematical problem-solving, and more scenarios. These tasks typically require combinatorial reasoning based on visual information and external knowledge. We synthesized extensive visual/textual reasoning data and integrated it into Qianfan-VL's post-training, significantly improving performance on reasoning and computation-related tasks as shown by benchmark results
Core Reasoning Application Scenarios
Complex Chart Understanding & Reasoning
- Data Analysis: Extract key information from complex charts for reasoning analysis
- Trend Prediction: Trend judgment and prediction based on historical data charts
- Correlation Reasoning: Cross-analysis and correlation reasoning of multi-chart data
- Statistical Computation: Statistical analysis and quantitative calculation of chart data
Mathematical Problem-Solving & Visual Reasoning
- Geometric Reasoning: Spatial figure relationship understanding and theorem application
- Formula Recognition: Precise recognition and understanding of complex mathematical formulas
- Step-by-step Solution: Clear problem-solving process and step presentation
- Logical Inference: Logic reasoning and problem-solving based on visual cues
Mathematical Problem-Solving Benchmark Performance
| Benchmark | Qianfan-VL-8B | Qianfan-VL-70B | InternVL3-8B | InternVL3-78B | Qwen2.5-VL-7B | Qwen2.5-VL-72B |
|---|---|---|---|---|---|---|
| Mathvista-mini | 69.19 | 78.6 | 69.5 | 71.1 | 69.5 | 70.1 |
| Mathvision | 32.82 | 50.29 | 21.48 | 33.48 | 29.61 | 34.8 |
| Mathverse | 48.4 | 61.04 | 30.96 | 43.32 | 43.68 | 49.26 |
| ChartQA Pro | 50.41 | 52 | 19.38 | 47.92 | 37.32 | 44.43 |
| HallusionBench | 51.72 | 54.52 | 49.7 | 40.5 | 49.2 | 40.2 |
| InHouse Dataset A | 59.87 | 71.78 | 26 | 43.40 | 40.64 | 41.47 |
| InHouse Dataset B | 61.33 | 75.6 | 26.81 | 39.7 | 36.25 | 42.65 |
Model Architecture Design & Technical Features
Through advanced multimodal architecture design and three major technical innovations, Qianfan-VL achieves domain-enhanced general vision-language capabilities
Overall Architecture

Qianfan-VL adopts advanced multimodal architecture, integrating industry best practices and autonomous innovations
Core Architecture Components
Language Model
Based on Llama 3.1 architecture, enhanced through vocabulary expansion and localization with 3T Chinese-English corpus, supporting mixed Chinese-English understanding
Vision Encoder
Initialized with InternViT, supporting dynamic patching for different resolution images, with maximum support for 4K resolution input
Cross-modal Fusion
MLP adapter achieves seamless bridging between vision and language modalities, ensuring accuracy and efficiency of information transfer
Technical Innovation & Features
Capability Enhancement Training Pipeline
Innovative four-stage training strategy that significantly enhances domain capabilities while maintaining general capabilities
High-Precision Data Synthesis Technology
Combines traditional CV models with programmatic generation to efficiently construct high-quality training data
Large-Scale Kunlun Chip Training
Completed training entirely using Baidu's self-developed Kunlun P800 chips, demonstrating the mature capabilities of domestic AI infrastructure
Capability Enhancement Training Pipeline
Innovative four-stage progressive training strategy that significantly enhances domain capabilities while maintaining general capabilities

Stage 1: Cross-modal Alignment - This stage aims to establish basic vision-language connection mapping, using a training strategy that only updates MLP Adapter while freezing Vision Encoder and LLM, trained with 100B tokens of general knowledge data. This stage is necessary, otherwise it will affect overall performance.
Stage 2: General Knowledge Injection - Focusing on the amount of injected data, trying to cover all training data, using full-parameter update training strategy with 2.66T tokens of general knowledge data. This stage builds the model's strong foundational capabilities while including sufficient proportion of text corpus to prevent catastrophic forgetting of LLM knowledge.
Stage 3: Domain-Enhanced Knowledge Injection - Carefully selecting high-quality data for domains to be enhanced, including task data for enhanced domains while integrating general data sampling to maintain general knowledge and prevent catastrophic forgetting, using full-parameter update training with 0.32T tokens of domain-specific data and general sampled data. This stage achieves significant enhancement of professional capabilities.
Stage 4: Post-training - This stage aims to improve instruction following ability and preference alignment, using full-parameter update training strategy with 1B tokens of instruction fine-tuning data. Uses high-quality alignment data including complex instruction following, writing, Q&A, programming, OCR, information extraction, mathematics, reasoning computation tasks, while incorporating sufficient pure text instruction fine-tuning data to maintain text model capabilities.
High-Precision Data Synthesis Technology
Constructs a data synthesis pipeline for multimodal tasks, covering core tasks such as document recognition, mathematical problem solving, chart understanding, table recognition, formula recognition, and natural scene OCR. Through refined pipeline design and intermediate process data construction, it achieves efficient production of high-quality training data
Multi-task Data Synthesis Pipeline
Document Recognition OCR Pipeline
- Comprehensive Analysis: Multi-dimensional analysis integrating layout, category, and content, supporting multiple languages and handwritten scanned documents
- Image-to-Markdown: Efficient conversion of single/multi-page documents to structured Markdown
- Document Q&A: Deep understanding supporting summarization, reasoning, and multi-turn dialogue
Mathematical Problem Solving OCR Pipeline
- Educational Data Preprocessing: Collect multilingual high-quality problem-solving data, standardize terminology and symbols, structure problems/conditions/steps/formulas
- Problem-Solving Data Synthesis: Combine knowledge systems to synthesize photo problem-solving scenario data through structured expression→LaTeX→HTML→image pipeline
- Visual Extraction Enhancement: For complex scenarios like charts, formulas, and geometry, construct high-quality data through formal description languages combined with HTML rendering
Chart Understanding Pipeline
- Data Expansion: Open source dataset sampling + Baidu Image Search API expansion + deduplication processing
- Chart Summary: Pre-trained VLM generates structured summaries containing visual and numerical information
- Two-stage Generation: Generate questions based on summaries → Generate answers based on questions and summaries
Table Recognition Pipeline
- Table Structuring: Precise recovery of image tables to HTML/LaTeX, supporting complex layouts like borderless tables and contract tables
- Table Q&A: Numerical computation, comparative analysis, and information retrieval based on table images
- Content Generation: Random table structure + Faker library/LLM filling + random cell merging with professional CSS theme rendering
Formula Recognition Pipeline
- Symbol Recognition: Precise recognition of mathematical symbols, Greek letters, and special notations
- Structure Parsing: Complex structures like fractions, radicals, superscripts/subscripts, matrices
- Multi-engine Rendering: MathJax/KaTeX ensuring rendering consistency
Natural Scene OCR Pipeline
- Background Filtering: Lightweight OCR model + image type detection to exclude samples with text/non-static content
- Scene Understanding: Semantic segmentation model + monocular depth estimation for region division and 3D structure
- Real Projection: Plane detection + perspective projection + random text style natural projection
Large-Scale Kunlun Chip Parallel Training
Based on Baidu's self-developed Kunlun P800 chips, constructed an industry-leading ultra-large-scale distributed training system, achieving efficient training through innovative parallel strategies and operator optimization
Cluster Scale
Training Data Scale
Scaling Efficiency
3D Parallel Training Strategy
Uses a combination of Data Parallelism (DP), Tensor Parallelism (TP), and Pipeline Parallelism (PP), with dynamic load balancing optimizing distribution based on model layer characteristics. Gradient synchronization optimization reduces AllReduce communication time by 60%, combined with ZeRO-3 state sharding technology for memory optimization. Pipeline scheduling uses 1F1B strategy with bubble rate controlled below 5%, sequence dimension partitioning halves long sequence training memory usage, dynamic batching adaptively adjusts batch size based on sequence length, and selective activation recomputation for checkpoint optimization.
Kunlun Chip Communication-Computation Fusion Technology
Architecture Advantages: In the P800 architecture, communication operators and matrix multiplication operators belong to different hardware units, forming a significant difference from traditional GPGPU architecture. In traditional GPU architecture, communication and computation often compete for the same hardware resources, leading to mutual blocking during execution. The P800 architecture achieves true communication-computation parallelism through hardware separation design of dedicated communication processing units and matrix multiplication processing units. This design brings core advantages of resource isolation, where communication operator execution is completely unaffected by matrix multiplication operators, avoiding resource competition in traditional architectures. Meanwhile, through parallel execution mechanisms, data transmission and matrix operations can be performed simultaneously, significantly improving hardware utilization. More importantly, this architecture can use overlap technology to mutually mask communication latency with computation processes.
GEMM Communication-Computation Fusion Technology: By establishing additional bypass streams (BypassStream), we can seamlessly integrate communication operators before and after matrix multiplication operations. The core idea of this mechanism is to establish an independent scheduling system, where bypass streams run independently of main computation streams without blocking the main matrix multiplication pipeline. Meanwhile, through data prefetching mechanisms, data communication is initiated in advance to ensure timely arrival of computation-required data. After computation completion, result communication transmission is immediately initiated, forming a complete pipeline.
Multi-stream Optimization Implementation: Taking AllGather and matrix multiplication fusion as an example, through fine data chunking strategies, deep fusion of computation and communication is achieved. Traditional methods require completing the entire AllGather operation first, waiting for all data transmission to finish before starting GEMM computation. The fusion method decomposes data into multiple blocks, with each data block immediately starting corresponding computation after communication completion, forming pipeline parallelism. When communication operators prepare atomic data blocks, matrix multiplication can immediately start operations without waiting for all data to be ready, achieving true pipeline parallelism.
Scenario Case Studies
Handwritten Text Recognition

Scene Text Recognition

颐和园公园南门800米/北侧距万柳高尔夫80米
心30米/距地铁巴沟站C出口10米
T·6271
Invoice Information Extraction

{
"发票号码": "0110020001",
"开票日期": "2021年10月",
"合计": "1565.05",
"价税合计": "1580.70",
"项目列表": [
{"项目名称": "成药*安宫牛黄丸", "数量": "1", "金额": "749.11"},
{"项目名称": "成药*益安宁丸", "数量": "1", "金额": "758.71"},
{"项目名称": "学药品制剂*藿香正气软胶囊", "数量": "2", "金额": "57.23"}
]
}
Quadratic Function Problem Solving
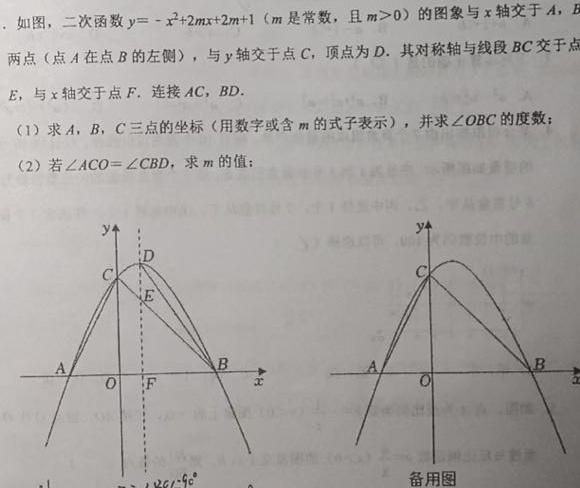
Find A, B coordinates: Intersections with x-axis require solving \( -x^2 + 2mx + 2m + 1 = 0 \)
Using quadratic formula: \( x = \frac{-2m \pm \sqrt{4m^2 + 8m + 4}}{-2} = \frac{-2m \pm \sqrt{(2m + 2)^2}}{-2} \)
Since \( m > 0 \), \( \sqrt{(2m + 2)^2} = 2m + 2 \)
First solution: \( x = \frac{-2m + 2m + 2}{-2} = -1 \)
Second solution: \( x = \frac{-2m - (2m + 2)}{-2} = 2m + 1 \)
Therefore: A(-1, 0), B(2m + 1, 0)
Find C coordinate: y-axis intersection, let x=0: \( y = 2m + 1 \)
Therefore: C(0, 2m + 1)
In triangle OBC:
• OB = 2m + 1 (distance from B to origin)
• OC = 2m + 1 (distance from C to origin)
• BC = \( \sqrt{(2m + 1)^2 + (2m + 1)^2} = (2m + 1)\sqrt{2} \)
Since OB = OC and OB² + OC² = BC², triangle OBC is an isosceles right triangle
Therefore: ∠OBC = 45°
First find vertex D coordinates: \( D(m, (m + 1)^2) \)
Find tangent of ∠ACO:
In right triangle ACO, opposite side AO=1, adjacent side CO=2m+1
\( \tan(\angle ACO) = \frac{AO}{CO} = \frac{1}{2m + 1} \)
Find tangent of ∠CBD:
Slope of line BC: \( k_{BC} = \frac{2m + 1}{-(2m + 1)} = -1 \)
Slope of line BD: \( k_{BD} = \frac{(m + 1)^2}{m - (2m + 1)} = -(m + 1) \)
\( \tan(\angle CBD) = \left| \frac{-(m + 1) - (-1)}{1 + (-1)[-(m + 1)]} \right| = \frac{m}{m + 2} \)
Since ∠ACO = ∠CBD: \( \frac{1}{2m + 1} = \frac{m}{m + 2} \)
Cross multiply: \( m + 2 = m(2m + 1) \)
Simplify: \( m + 2 = 2m^2 + m \)
Reduce: \( 2m^2 = 2 \Rightarrow m^2 = 1 \)
Since \( m > 0 \): m = 1
Verification: When m=1, \( \tan(\angle ACO) = \frac{1}{3} \), \( \tan(\angle CBD) = \frac{1}{3} \), equal
Answer:m = 1
Mathematical Formula Recognition
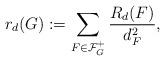
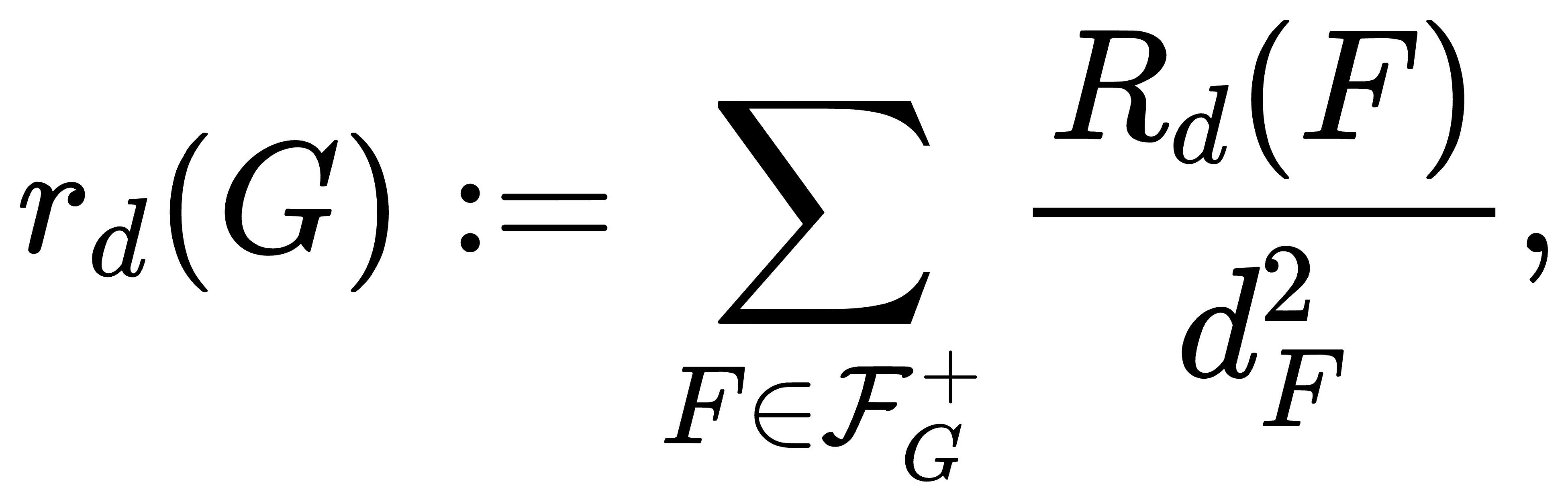
Document Content Understanding

Table Structure Understanding
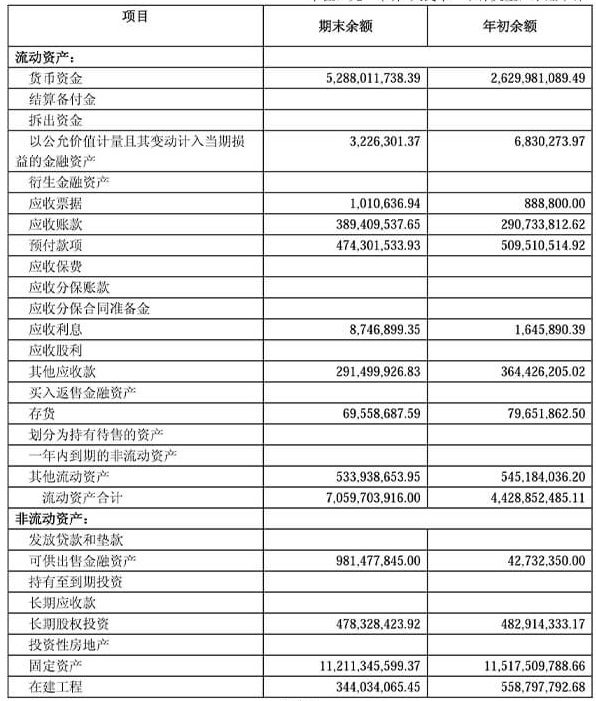
<table border="1">
<thead>
<tr>
<th>Items</th> <th>Ending Balance</th> <th>Beginning Balance</th>
</tr>
</thead>
<tbody>
<tr> <td colspan="3">Current Assets:</td> </tr>
<tr> <td>Monetary Funds</td> <td>5,288,011,738.39</td> <td>2,629,981,089.49</td> </tr>
<tr> <td>Settlement Provisions</td> <td></td> <td></td> </tr>
<tr> <td>Placements with Other Banks</td> <td></td> <td></td> </tr>
<tr> <td>Financial Assets at Fair Value</td> <td>3,226,301.37</td> <td>6,830,273.97</td> </tr>
<tr> <td>Derivative Financial Assets</td> <td></td> <td></td> </tr>
<tr> <td>Notes Receivable</td> <td>1,010,636.94</td> <td>888,800.00</td> </tr>
<tr> <td>Accounts Receivable</td> <td>389,409,537.65</td> <td>290,733,812.62</td> </tr>
<tr> <td>Prepayments</td> <td>474,301,533.93</td> <td>509,510,514.92</td> </tr>
</tbody>
</table>
| Items | Ending Balance | Beginning Balance |
|---|---|---|
| Current Assets: | ||
| Monetary Funds | 5,288,011,738.39 | 2,629,981,089.49 |
| Settlement Provisions | — | — |
| Placements with Other Banks | — | — |
| Financial Assets at Fair Value | 3,226,301.37 | 6,830,273.97 |
| Derivative Financial Assets | — | — |
| Notes Receivable | 1,010,636.94 | 888,800.00 |
| Accounts Receivable | 389,409,537.65 | 290,733,812.62 |
| Prepayments | 474,301,533.93 | 509,510,514.92 |
Chart Data Analysis
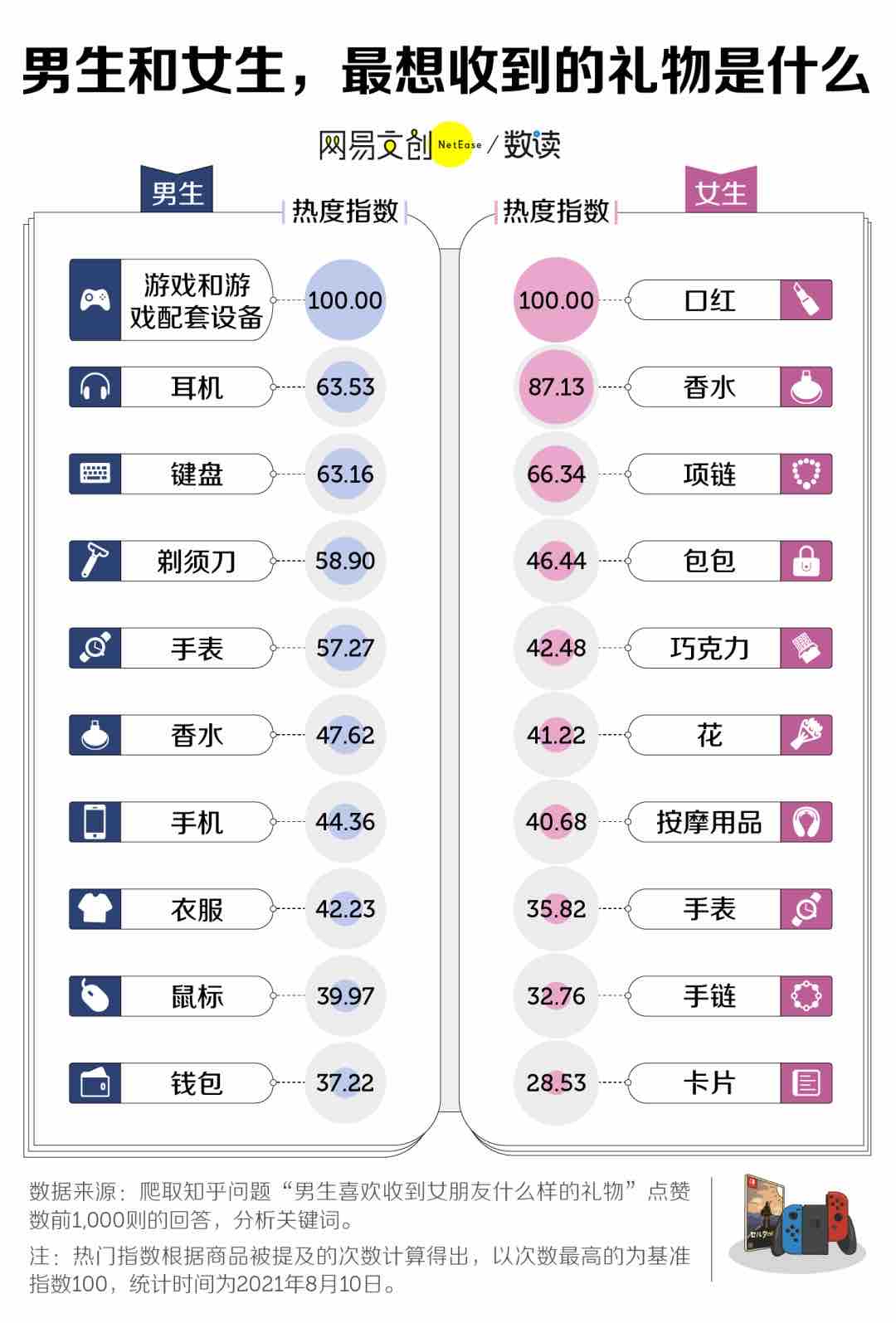
The user needs help choosing a Valentine's Day gift for Xiao Ming, who is male. First, I need to recall the previously mentioned gifts that boys most want to receive. According to the provided chart, the gift with the highest popularity index among boys is "gaming and gaming accessories" with a popularity index of 100.00, followed by headphones 63.53, keyboards 63.16, razors 58.90, watches 57.27, perfume 47.62, mobile phones 44.36, etc.
Now looking at the options: a) iPhone 17, belongs to mobile phone category, mobile phones have a popularity index of 44.36 among boys. Although higher than perfume and watches, mobile phones don't have a particularly high popularity index among boys, especially since iPhone 17 might be quite expensive, and mobile phones themselves might not be as popular among boys as gaming equipment. b) Dior perfume, among girls' most wanted gifts, perfume has a popularity of 87.13, while boys' interest in perfume is only 47.62, clearly boys have lower interest in perfume, so perfume given by girls might not be very suitable for boys. c) A beautiful bouquet of flowers, among girls' most wanted gifts there are flowers with popularity 41.22, but boys might not be very interested in flowers, usually boys might not like receiving flowers as gifts. d) Chocolate gift set, among girls' most wanted gifts there's chocolate with popularity 42.48, similarly boys' interest in chocolate might not be as high as gaming equipment, headphones, etc.
However, here we need to consider that for Valentine's Day when girls give gifts to boys, usually boys prefer practical or interest-related items. Gaming and gaming equipment have the highest popularity, but there are no gaming devices in the options, so among the remaining options, mobile phones (iPhone 17) belong to electronic products, which might be more suitable than perfume, chocolate, and flowers. Although mobile phones have a popularity index of 44.36 among boys, compared to other options, chocolate gift set (d) has popularity 42.48, mobile phone (a) 44.36, mobile phones might be slightly higher? But we need to confirm whether the mobile phone in the options is the type boys like. Also, for Valentine's Day, boys might expect more practical or meaningful gifts, mobile phones as electronic products might be more popular than perfume and flowers because boys might not like perfume much, flowers might seem cliche, chocolate gift sets although girls like them, boys might find them ordinary. While gaming equipment has the highest popularity, but it's not in the options, so we can only choose from existing options. Therefore, option a) iPhone 17 might be more suitable, because mobile phones have higher popularity among boys than perfume, chocolate, and flowers, although not as high as gaming equipment, but other options are worse.
</think>
According to the chart data, among the gifts boys most want to receive, mobile phones have a popularity index of 44.36, higher than perfume (47.62), chocolate gift sets (42.48), and flowers (41.22).
Option Analysis:
- a) iPhone 17: Belongs to mobile phone category, fits boys' preference for electronic products, popularity index is at a high level among boys' gifts (second only to gaming equipment).
- b) Dior perfume: Girls' interest in perfume (87.13) is much higher than boys' (47.62), and boys have lower interest in perfume.
- c) A beautiful bouquet of flowers: Boys' interest in flowers is significantly lower than girls' (boys' flower popularity 41.22), usually not considered a preferred gift for boys.
- d) Chocolate gift set: Girls' interest in chocolate (42.48) is higher than boys' (47.62), and chocolate as a gift is more "mainstream" rather than boys' core interest.
The most suitable gift is a) iPhone 17
Answer: a
</answer>
Stock Trend Analysis
Video Understanding
Quick Start
Functional Example Code
For complete usage examples and code, please refer to our Cookbook: Qianfan-VL Example Notebook
API Parameter Description
For detailed API parameter descriptions and calling documentation, please refer to: Qianfan ModelBuilder API Documentation
Summary
Qianfan-VL is positioned as a domain-enhanced general multimodal large language model, offering multiple specifications of 3B, 8B, and 70B, achieving multi-scale and full-scenario application coverage. Focusing on B2B customer needs, it significantly enhances multiple task capabilities in intelligent office and K-12 education scenarios, including OCR recognition, document parsing, photo problem-solving, chart understanding, and complex table parsing. For scenarios requiring complex reasoning, the thinking capability can be enabled on 8B and 70B models to further enhance model performance.
On the technical level, it adopts multi-stage progressive continuous pre-training technology, continuously enhancing the proportion of domain-specific data while maintaining general capabilities, thereby achieving significant improvement in domain capabilities. Based on traditional small models and programmatic synthesis methods, the Qianfan-VL team has constructed a large amount of high-precision training data, significantly increasing data density for long-tail scenarios and improving model generalization. All model sizes were completed through large-scale parallel training powered by 5000+ Kunlun chips, and these models can perform efficient inference on Kunlun chips, GPUs, and other processors.
The Qianfan-VL series models demonstrate good generalizability among models of the same parameter size, with excellent performance on specialized domain benchmarks and even better performance on real business benchmarks. Through the domain enhancement technology route, Qianfan-VL provides high-performance solutions that combine both generalizability and specialization for enterprise-level multimodal AI applications.